카테고리 없음
뉴스기사 크롤링하여 핵심내용 추출 프로젝트 (1)
- -
뉴스기사를 모두 긁어와도 양이 너무 많고, 그 많은 뉴스기사들을 읽기에는 시간이 너무 많이 걸릴 것 같다는 생각이 들었습니다. 그래서 저는 파이썬으로 뉴스기사를 모두 스크랩하여 엑셀에 보기쉽게 넣는 프로그램을 하나 만들예정입니다
하지만 이렇게되면 기존의 크롤링과는 동일한 방법이겠죠... 저는 이 기사내용의 핵심 단어 10개정도를 뽑아
뉴스내용대신 이 단어들로 수 많은 뉴스기사들을 모두 읽어볼 필요가 없이 키워드로 흐름을 파악할 수 있도록
프로그램을 설계해보겠습니다~

핵심은 키워드 뉴스입니다!
아 그리고

얼마전에 급조한 저희 팀로고 입니다. 간단히 TET라 합니다ㅎㅎ
다양한 프로젝트를 진행하고 블로그에 결과와 코드까지 모두 무료로 배포할 예정이니 많이 봐주세요!

일단 결과물은 이렇게 나올 예정입니다.
뉴스의 제목과 신문회사, 하이퍼링크, 마지막으로 이 프로그램의 핵심인 키워드가 있습니다.

이렇게 수많은 기사들을 키워드로 볼 수 있고, 맨 밑에는 전체적으로 어떤 키워드가 많이 쓰였는지를 분석하여
빠르게 뉴스를 읽을 수 있습니다.
프로그램 이름은 NewScraper 로 대충 지었습니다ㅋㅋㅋㅋㅋㅋㅋㅋㅋ
import requests
from bs4 import BeautifulSoup
import re
import openpyxl
sheet = None
class NaverNewsParser:
def __init__(self, url):
self.menu_URLs = []
self.soup = None
self.url = ''
self.sheet = None
self.fileType = ''
self.filePath = ''
self.max_content_cnt = 0
self.option_topic_dic = {}
self.menu_url_dic = {'속보':'https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=001#&date=%2000:00:00&',
'정치':'https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=100#&date=%2000:00:00&',
'경제':'https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=101#&date=%2000:00:00&',
'사회':'https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=102#&date=%2000:00:00&',
'생활/문화':'https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=103#&date=%2000:00:00&',
'세계':'https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=104#&date=%2000:00:00&',
'IT/과학':'https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=105#&date=%2000:00:00&'}
self.sub_menu_url_dic = [
{'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=264',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=265',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=268',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=266',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=267',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=269'
},
{'청와대':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=264',
'국회/정당':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=265',
'북한':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=268',
'행정':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=266',
'국방/외교':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=267',
'정치일반':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=269'
},
{'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=264',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=265',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=268',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=266',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=267',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=269'
},
{'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=264',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=265',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=268',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=266',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=267',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=269'
},
{'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=264',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=265',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=268',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=266',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=267',
'-':'https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=100&sid2=269'
},
]
self.url = url
self.index = 2
self.bef_title = ''
self.page_option = 'min'
def getSoup(self, url, page=-1): # soup 객체를 재정의
if page != -1:
print(url + 'page=' + str(page))
response = requests.get(url + 'page=' + str(page))
else:
print(url)
response = requests.get(url)
html = response.text
return BeautifulSoup(html, 'html.parser')
def getContent(self): # 뉴스 본문 복사
return self.soup.find('div', {'id':'articleBodyContents'})
def refineContet(self, pure): # 뉴스기사 전처리
pure = re.sub('<script.*?>.*?</script>', '', str(pure), 0, re.I|re.S)
pure = re.sub('<!-- .*? -->', '', str(pure), 0, re.I|re.S)
pure = re.sub('▶.*', '', str(pure), 0, re.I|re.S)
content = re.sub('<.+?>', '',str(pure), 0).strip()
return str(content)
def findMaxPage(self): # 최대 페이지 개수 정의
last_page_soup = self.getSoup(self.url, 987656) # max page
#return last_page_soup.find('div', {'id':'paging'}).find('strong').get_text()
# if web page is Dynamic, code is not work!!
return 200
def isAllEng(self, string): # 문자열 절반이상이 영어인지 검색(영자신문 제외하기 위해)
cnt = 0
for ch in string:
if ord('A') <= ord(ch) <= ord('z'):
cnt += 1
if cnt >= len(string)/2:
return True
return False
def writeContextsOnPage(self, page='1'): # 한 페이지에 해당하는 뉴스들을 엑셀로 모두 추출
cur_soup = self.getSoup(self.url, page)
# print(cur_soup.find('div', {'class':'list_body newsflash_body'}))
if self.page_option == 'min':
print('!!!!')
news_sections = cur_soup.find('div', {'class':'list_body newsflash_body'}).find_all('ul')
# print(news_sections)
for news_section in news_sections:
for news in news_section:
try :
if self.index > self.max_content_cnt:
break
target_title = news.find('dl').find_all('dt')[1].get_text().strip()
if target_title == self.bef_title:
continue
if self.isAllEng(target_title) == True: # 영어 필터링
continue
self.bef_title = target_title
target_writer = news.find('dl').find('dd').find('span',{'class':'writing'}).get_text().strip()
target_url = news.find('dl').find_all('dt')[1].find('a').attrs['href']
print(target_title)
print(target_writer)
# print(target_url)
target_soup = self.getSoup(target_url)
pure_content = target_soup.find('div', {'id':'articleBodyContents'})
content = self.refineContet(pure_content)
print(content)
print('\n=============================' + str(self.index) + '=====================')
self.sheet['A'+ str(self.index)] = target_title
self.sheet['B'+ str(self.index)] = target_writer
self.sheet['C'+ str(self.index)] = target_url
self.index += 1
except AttributeError as e:
# 잠제적 에러
pass #print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! AttributeError', e)
except IndexError as e:
pass #print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! IndexError', e)
except NameError as e:
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! NameError', e)
elif self.page_option == 'max':
# news_sections = cur_soup.find('div', {'class':'list_body newsflash_body'}).find_all('ul')
pass
def scrap(self): # 페이지 수를 파악하고 해당 테마뉴스의 모든 페이지를 검사한다
for option_topic in self.option_topic_list:
self.url = self.menu_url_dic[option_topic]
max_page = self.findMaxPage()
for p in range(1, max_page+1):
if self.index > self.max_content_cnt:
break
self.writeContextsOnPage(str(p))
def setFile(self, fileType, filePath): # 엑셀 저장위치
self.fileType = fileType
self.filePath = filePath
self.book = openpyxl.load_workbook(filePath)
self.sheet = self.book.active
def setMaxContentCnt(self, max_content_cnt): # 추출할 뉴스 최대개수
self.max_content_cnt = max_content_cnt
def setOptions(self, option_topic_list): # 테마설정
self.option_topic_list = option_topic_list
def __del__(self): # 엑셀파일에 저장
self.sheet.column_dimensions['A'].width = 60
self.sheet.column_dimensions['B'].width = 15
self.sheet.column_dimensions['C'].width = 90
print('sav!!')
self.book.save(self.filePath)
print('saved!!')
nnp = NaverNewsParser("https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=001&") # 객체생성 (생성자 인자로 네이버 뉴스 메인홈페이지)
nnp.setOptions(['속보']) # 뉴스 테마 입력
nnp.setFile('xls', r"C:\Users\bsjo9\OneDrive\바탕 화면\crowl.xlsx") # 저장할 위치
nnp.setMaxContentCnt(300) # 긁어올 최대 뉴스개수
nnp.scrap() # 뉴스 스크랩&저장 실행
del nnp # 객체 삭제
print('end')
코드는 간단(????)하게 요렇게 만들었고
NaverNewsParser라는 클래스를 만들어서 사용하는 입장에서 더 편하게 이용하게끔 만들었습니다
nnp = NaverNewsParser("https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=001&") # 객체생성 (생성자 인자로 네이버 뉴스 메인홈페이지)
nnp.setOptions(['속보']) # 뉴스 테마 입력
nnp.setFile('xls', r"C:\Users\bsjo9\OneDrive\바탕 화면\crowl.xlsx") # 저장할 위치
nnp.setMaxContentCnt(300) # 긁어올 최대 뉴스개수
nnp.scrap() # 뉴스 스크랩&저장 실행
del nnp # 객체 삭제
이 부분이 코드의 메인함수 입니다.
생성자로 처음 페이지의 주소를 넘겨주고
setOptions라는 함수를통해 속보, 정치, 경제, 사회, 과학 등 테마별로 스크랩할 수 있게 만듭니다.
다음으로 setFile함수는 엑셀파일을 저장할 위치를 설정합니다
setMaxContentCnt함수로 스크랩할 최대 뉴스 개수를 설정할 수 있습니다
이제 클래스 내부구조를 보면 가장 핵심이 되는 코드는 scrap과 writeContextsOnPage 멤버함수 입니다
scrap은 다음과 같이 생겼습니다.
NaverNewsParser.scrap(self)
여기서 fin
def scrap(self): # 페이지 수를 파악하고 해당 테마뉴스의 모든 페이지를 검사한다
for option_topic in self.option_topic_list: # 테마 리스트를 검사
self.url = self.menu_url_dic[option_topic]
max_page = self.findMaxPage() # 최대 페이지수 설정(기본값 200페이지)
for p in range(1, max_page+1): # 최대 페이지까지 반복
if self.index > self.max_content_cnt: # 만약 스크랩할 최대 뉴스개수를 넘겨버리면 멈춤
break
self.writeContextsOnPage(str(p)) # p번째 페이지의 모든 뉴스기사들을 스크랩dMaxPage()로 최대 페이지를 구하는 과정이 나오는데 이게 왜 필요하냐면
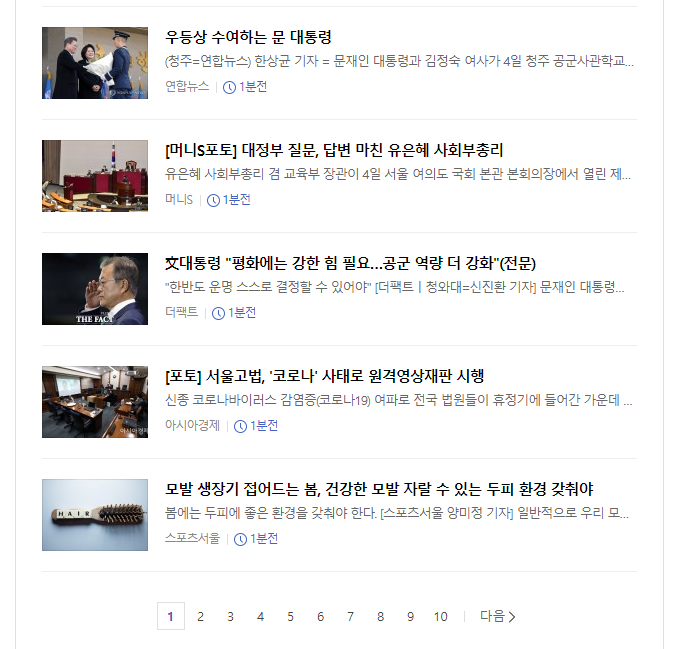
이렇게 네이버 뉴스에 들어가면 1페이지에는 URL마지막엔 page라는 파라이미터에 001이
붙는다는 것을 알 수 있습니다.

그럼 우리는 짐작으로 page=n 이면 n페이지로 간다는 것을 알게됩니다. 그럼 저는 이걸로 어떻게 최대페이지를
구하려했냐 면
page에 엄청 큰 수를 넣습니다 987654321를 넣으면

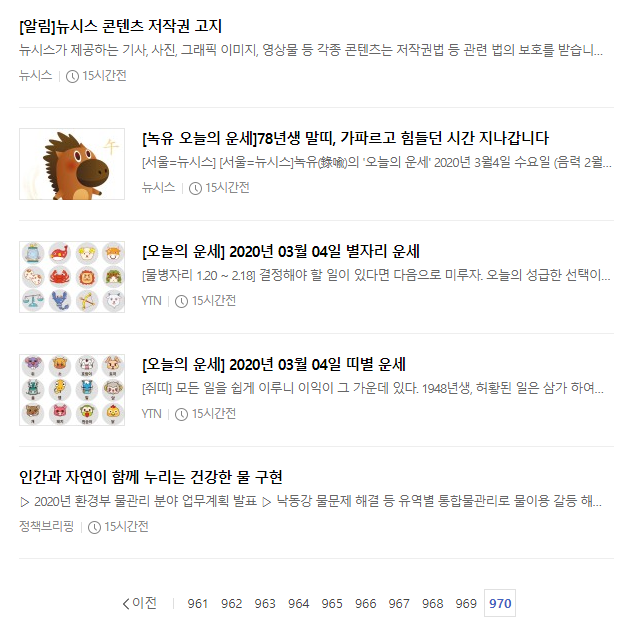
이렇게 마지막 페이지가 나오게됩니다!!
방금 위의 내용을 코드로 구현한 것이 바로 아래입니다
NaverNewsParser.scrap(self)
def findMaxPage(self): # 최대 페이지 개수 정의
last_page_soup = self.getSoup(self.url, 987656) # max page
return last_page_soup.find('div', {'id':'paging'}).find('strong').get_text()getSoup() 의 두번째 인자는 페이지수를 받아서 page=987656 이라는 파라미터를 만들게끔 설계했습니다~
def getSoup(self, url, page=-1): # soup 객체를 재정의
if page != -1:
print(url + 'page=' + str(page))
response = requests.get(url + 'page=' + str(page))
else:
print(url)
response = requests.get(url)위처럼 getSoup를 구현하여서 간단하게 문자열만 덧붙이는 식으로 코드를 작성했습니다.
하지만 최대페이지를 저렇게 구하면 속보 테마말고 정치테마였나? 어떤 특정테마가 들어가면 작동이 잘 안될때가 있어서 그냥 주석처리하고 최대페이지를 200으로 고정했습니다....ㅋㅋㅋㅋㅋㅋ
다시 scrap() 함수로 돌아와서 writeContextsOnPage() 에 인자값으로 1부터 최대페이지(200) 까지를 넣으면서 호출하고 있습니다.
writeContextsOnPage함수는 인자값에 해당하는 페이지의 기사를 모두 스크랩하는 것입니다
NaverNewsParser.writeContextsOnPage(self, page='1')
def writeContextsOnPage(self, page='1'): # 한 페이지에 해당하는 뉴스들을 엑셀로 모두 추출
cur_soup = self.getSoup(self.url, page)
# print(cur_soup.find('div', {'class':'list_body newsflash_body'}))
if self.page_option == 'min':
news_sections = cur_soup.find('div', {'class':'list_body newsflash_body'}).find_all('ul')
# print(news_sections)
for news_section in news_sections:
for news in news_section:
try:
if self.index > self.max_content_cnt:
break
target_title = news.find('dl').find_all('dt')[1].get_text().strip()
if target_title == self.bef_title:
continue
if self.isAllEng(target_title) == True: # 영어 필터링
continue
self.bef_title = target_title
target_writer = news.find('dl').find('dd').find('span',{'class':'writing'}).get_text().strip()
target_url = news.find('dl').find_all('dt')[1].find('a').attrs['href']
target_soup = self.getSoup(target_url)
pure_content = target_soup.find('div', {'id':'articleBodyContents'})
content = self.refineContet(pure_content)
print('\n=============================' + str(self.index) + '=====================')
self.sheet['A'+ str(self.index)] = target_title
self.sheet['B'+ str(self.index)] = target_writer
self.sheet['C'+ str(self.index)] = target_url
self.index += 1
except AttributeError as e:
# 잠제적 에러
pass #print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! AttributeError', e)
except IndexError as e:
pass #print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! IndexError', e)
except NameError as e:
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! NameError', e)요렇게 구연했습니다...
여기서 변수 news 는

빨간색 블록 하나하나를 의미합니다, 이것들이 List형태로 들어가있어서 반복문
for news in news_section: 를 통해 이 블록 하나하나를 news 변수로 접근이 가능하게 됩니다
근데 상위 for문에 for news_section in news_sections: 를 넣은 이유는


이렇게 두 구역으로 나누어져있어서 어쩔수 없이 section을 반복문으로 접근한 것입니다... (현재는 2개인데 3개 나올 가능성도 고려했기 때문)
이제 writeContextsOnPage함수의 세부 동작은 (링크) 다음편을 참고해 주세용
Contents
소중한 공감 감사합니다