Projects
OCR를 이용한 동영상속 텍스트 추출 프로젝트 (1)
- -

kernel = np.ones((2, 2), np.uint8)
morph = cv2.morphologyEx(gray, cv2.MORPH_GRADIENT, kernel) # 2 ================ 경계선 찾기
필자는 사실 구독자 40만 인기유튜버 '몽자'를 매우 좋아합니다.
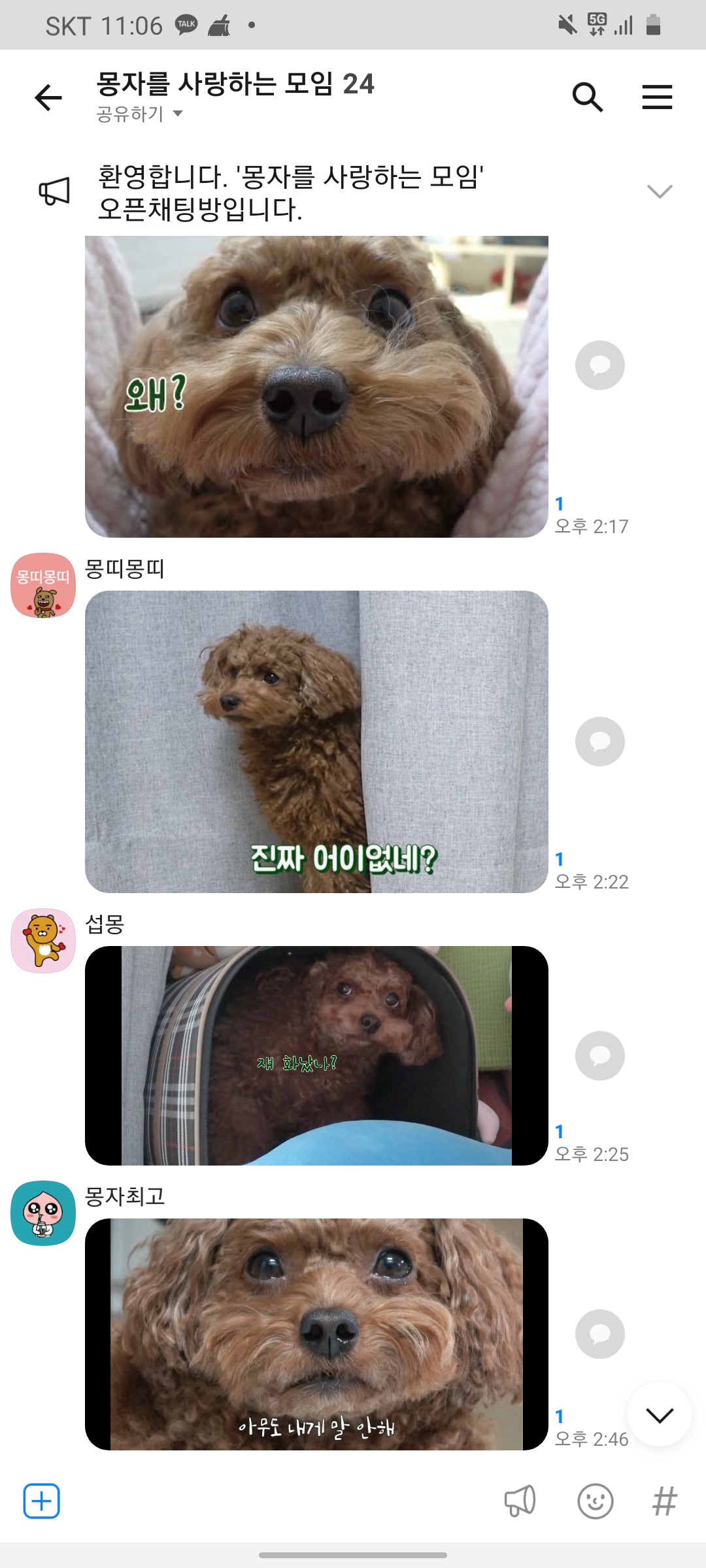

이렇게 오픈채팅방에서도 활발히 활동을 하는데, 오픈채팅방에서는 짤로 대화한다는 특이한 암묵의 규칙(?)이 있습니다.
그래서 필자도 짤로 대화를 하려하는 도중, 적절한 상황에 맞는 짤을 찾는데 시간이 많이 걸린다는 것을 느꼇습니다.
그래서 문득 이 텍스트를 검색할 수 있었으면 얼마나 좋았을까? 라는 생각이 들었습니다. 그리고 짤을 찾는 과정도
유튜브에 동영상을 보면서 스크린샷으로 저장하는 방식이었는데, 유튜브 동영상을 자동으로 분석하여 적절한 짤을 자동으로 추출까지 했으면 좋겠다는 생각이들었습니다.
그래서 동영상을 분석해 자동으로 짤을 추출하고 그 짤에 있는 텍스트를 검색할 수 있는 앱을 한번만들어보겠다는 야심찬 목표를 가지고 프로젝트를 진행합니다~
저는 자료형에 영향받지 않고 로직에만 집중할 수 있는 Python으로 개발을 하였고,
텍스트인식에는 영상처리와 인공지능이 필요하기 때문에 OpenCV(영상처리 라이브러리)와 Keras(딥러닝 프레임워크)를 사용했습니다
목표는 동영상을 분석하여 짤을 추출해야합니다. 그러기 위해선 다음과 같은 순서로 작업해야합니다.
1) Opencv로 단어뭉치로 추정되는 것들을 추출한다
2) 추출된 것들이 정말로 단어뭉치인지 아닌지를 분류하여 인공신경망을 학습시킨다
3) 학습된 인공신경망은 단어분류를 잘하게 된다
여기서 2)의 과정이 필요한 이유는


이렇게 한가지 기준으로 판단하게 되면 상황에 따라 검출이 잘될수도, 안될수도 있기 때문입니다.

그래서 저는 이렇게 text는 글씨사진, no_text는 글씨덩어리로 착각한 것들, 그리고 middle은 글씨긴 글씨인데 조금 잘린것들을 저장했습니다
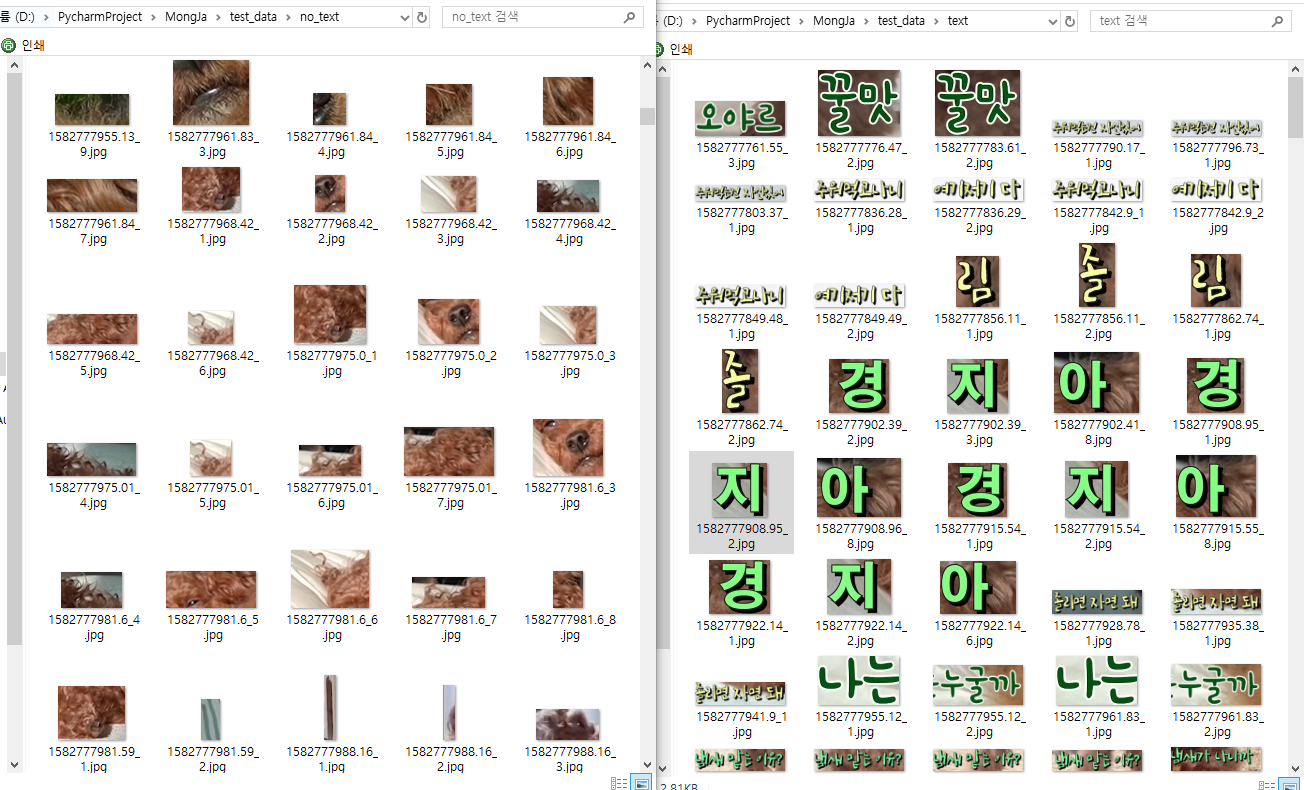
이렇게 노가다로 분류하는 작업이 조금 필요합니다...... ㅋㅋㅋㅋㅋㅋ
원래는 동영상을 분석해 글씨를 추출하지만 일단 사진부터 분석을 하겠습니다
사진속에 텍스트를 검출하는 프로그램은 cv_core.py라는 파이썬 파일에 코딩하였습니다
# -*- coding: utf-8 -*-
import cv2
import numpy as np
def selectWords(img):
# org = cv2.imread('capture4.png', cv2.IMREAD_COLOR)
org = img
# org = cv2.resize(org, dsize=(0,0), fx=0.5, fy=0.5)
gray = cv2.cvtColor(org, cv2.COLOR_BGR2GRAY) # ================ 1 gray scale로 변환
kernel = np.ones((52, 2), np.uint8)
kernel2 = np.ones((6, 15), np.uint8)
roi_list = []
morph = cv2.morphologyEx(gray, cv2.MORPH_GRADIENT, kernel) # 2 ================ 경계선 찾기
thr = cv2.adaptiveThreshold(morph, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY_INV, 3, 30) # 3 ================ 임계처리
morph2 = cv2.morphologyEx(thr, cv2.MORPH_CLOSE, kernel2) # 4 ================ 뭉게기
contours, _ = cv2.findContours(morph2, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 5 ================ 특징점 찾기
org2 = cv2.copyMakeBorder(org, 0, 0, 0, 0, cv2.BORDER_REPLICATE)
for cnt in contours:
try:
x, y, w, h = cv2.boundingRect(cnt)
if w > 5 and 30 < h < 100:
# print(w, h)
roi = org2[y:y + h, x:x + w]
# cv2.imshow('roi', roi)
roi_list.append(roi)
cv2.rectangle(org, (x, y), (x+w, y+h), (255, 0, 0), 2)
except Exception as e:
pass
cnt = 0 # print all pieces
'''for r in roi_list:
cnt += 1
cv2.imshow(str(cnt), r)'''
cv2.imshow('org', org)
cv2.imshow('roi_list', roi_list)
cv2.imshow('gray', gray)
cv2.imshow('morph', morph)
cv2.imshow('morph2', morph2)
cv2.imshow('thr', thr)
return org, roi_list, gray, morph, morph2, thr
※ 참고로 imshow부분은 결과를 확인하는 부분이기 때문에 주석처리해도 무방합니다.
일단 위 코드를 말로 풀어보면 다음과 같습니다
맨 처음에 사진하나를 가져오고
a) 이미지를 흑백처리한다 (gray)
b) 이미지 경계부분을 찾는다 (moph)
c) 진한 경계부분만 추출한다 (thr)
d) 경계부분을 옆으로 번지게 한다
e) 그 중 뭉텅이로 있는 부분을 추출한다
간단히 말하면 아래와 같습니다






그럼 이제부터 코드 한줄한줄 분석해보겠습니다~~
1) Opencv로 단어뭉치로 추정되는 것들을 추출한다
# -*- coding: utf-8 -*-
import cv2
import numpy as np맨 처음은 opencv와 numpy를 import 합니다. Numpy는 행렬연산 라이브러리인데, opencv에서는 이미나 동영상을 일반 배열이 아닌 행렬로 계산하기 때문에 이 둘은 짝꿍입니다. 위에 utf-8은 한글주석을 허용해달라는 뜻입니다.
def selectWords(img):
# org = cv2.imread('capture4.png', cv2.IMREAD_COLOR)
org = img
# org = cv2.resize(org, dsize=(0,0), fx=0.5, fy=0.5)
gray = cv2.cvtColor(org, cv2.COLOR_BGR2GRAY) # ================ 1 gray scale로 변환
kernel = np.ones((52, 2), np.uint8)
kernel2 = np.ones((6, 15), np.uint8)
roi_list = []
morph = cv2.morphologyEx(gray, cv2.MORPH_GRADIENT, kernel) # 2 ================ 경계선 찾기
thr = cv2.adaptiveThreshold(morph, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY_INV, 3, 30) # 3 ================ 임계처리
morph2 = cv2.morphologyEx(thr, cv2.MORPH_CLOSE, kernel2) # 4 ================ 뭉게기
contours, _ = cv2.findContours(morph2, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 5 ================ 특징점 찾기
org2 = cv2.copyMakeBorder(org, 0, 0, 0, 0, cv2.BORDER_REPLICATE)
for cnt in contours:
try:
x, y, w, h = cv2.boundingRect(cnt)
if w > 5 and 30 < h < 100:
# print(w, h)
roi = org2[y:y + h, x:x + w]
# cv2.imshow('roi', roi)
roi_list.append(roi)
cv2.rectangle(org, (x, y), (x+w, y+h), (255, 0, 0), 2)
except Exception as e:
pass
cnt = 0 # print all pieces
'''for r in roi_list:
cnt += 1
cv2.imshow(str(cnt), r)'''
cv2.imshow('org', org)
cv2.imshow('roi_list', roi_list)
cv2.imshow('gray', gray)
cv2.imshow('morph', morph)
cv2.imshow('morph2', morph2)
cv2.imshow('thr', thr)
return org, roi_list, gray, morph, morph2, thr
다음은 이 프로그램의 핵심인 selectWords함수 입니다. 저는 인자값으로 img를 받은이유가 나중에 동영상을 처리하면서 frame하나하나를 함수로 넘기기때문인데, 지금은 동영상으로 하지 않기때문에 없애고 imread()부분의 주석을 풀어도 됩니다.
이제 이함수의 동작원리를 꼼꼼히 살펴보겠습니다.
# org = cv2.imread('capture4.png', cv2.IMREAD_COLOR)
org = img
# org = cv2.resize(org, dsize=(0,0), fx=0.5, fy=0.5)맨 윗 부분은 아까도 말씀드렸다시피 주석을 해제해도 무방합니다.
org = cv2.imread('capture4.png', cv2.IMREAD_COLOR)
# org = cv2.resize(org, dsize=(0,0), fx=0.5, fy=0.5)이렇게 바꿔도 된다는 말이죠~ 밑에 resize는 사진의 크기가 너무크면 반만큼 줄인다는 뜻인데 사진크기는 적당하여 그냥 주석처리 했습니다.
원본사진을 불러왔으면 다음 할 일은
a) 이미지를 흑백처리한다 (gray)
입니다. Opencv에서는 대부분의 영상처리작업의 input값이 사진, 동영상의 grayscale(흑백)이기 때문에 전처리를 해야합니다.
gray = cv2.cvtColor(org, cv2.COLOR_BGR2GRAY) # ================ 1 gray scale로 변환코드는 간단히 이렇게 한줄로 가능합니다. 그럼 이제 gray라는 변수(numpy 배열)에 아래와 같은 사진이 저장됩니다

b) 이미지 경계부분을 찾는다 (moph)
다음은 이미지의 경계를 찾는 작업을 할 것입니다. 경계를 찾기 위해서 모폴로지연산을 하겠습니다.
모폴로지연산방법은 팽창(dilation), 침식(erosion) 등 매우 다양한데, 그중 gradient라는 방법을 사용했습니다.

gradient는 dilate결과와 erosion결과의 차(sub) 입니다. 코드로 보면
morph = cv2.morphologyEx(gray, cv2.MORPH_GRADIENT, kernel) # 2 ================ 경계선 찾기이 한줄이 다 입니다ㅎㅎ (파이썬 만세입니다 ㅋㅋㅋㅋ)
첫번째 인자는 입력 이미지값(grayscale이여야만 합니다), 두번째는 연산방법, 세번째는 커널입니다.
커널은 경계선의 크기(?)라 할 수 있습니다.


왼쪽은 2x2 커널, 오른쪽은 22x12커널인데 오른쪽이 경계선이 좀더 두껍게 나온 경향이 있습니다.
저희는 글씨를 인식해야하기 때문에 2x2커널인 왼쪽이 더 필터링이 잘 되었다고 생각할 수 있겠죠!
nxm커널은 n이 커지면 세로로, m이 커지면 가로로 경계선이 번집니다.
kernel = np.ones((52, 22), np.uint8)만약 커널크기를 이렇게 55x22로 바꾸면 결과값은

이렇게 됩니다...ㅋㅋㅋㅋㅋ 그러니 커널크기를 적절히 조절하는 것이 매우 중요합니다!
c) 진한 경계부분만 추출한다 (thr)
이제 moph 변수에는 다음과 같은 사진이 있겠죠

우리는 "어 여기?"라는 텍스트를 추출하고 싶습니다. 그래고 이 텍스는 주변 환경보다 훨씬 진하다는 것을 알 수있죠
글씨부분이 주변보다 더 진하기 때문에 Threshold기법을 사용하겠습니다. Threshold란 임계점이란 뜻을 가지고 있습니다.
특정 임계치를 넘는 것들만 필터링하기 위해 사용하는 거죠

위 그림은 threshold의 다양한 연산방법에 따른 결과들입니다
thr = cv2.adaptiveThreshold(morph, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY_INV, 3, 30) # 3 ================ 임계처리코드는 또 한줄입니다~~ threshold 와 adaptiveThreshold는 조금 차이가 있으니
https://opencv-python.readthedocs.io/en/latest/doc/09.imageThresholding/imageThresholding.html
이미지 임계처리 — gramman 0.1 documentation
기본 임계처리 이진화 처리는 간단하지만, 쉽지 않은 문제를 가지고 있다. 이진화란 영상을 흑/백으로 분류하여 처리하는 것을 말합니다. 이때 기준이 되는 임계값을 어떻게 결정할 것인지가 중요한 문제가 됩니다. 임계값보다 크면 백, 작으면 흑이 됩니다. 기본 임계처리는 사용자가 고정된 임계값을 결정하고 그 결과를 보여주는 단순한 형태입니다. 이때 사용하는 함수가 cv2.threshold() 입니다. cv2.threshold(src, thresh, maxval
opencv-python.readthedocs.io
이 곳을 참고하시기 바랍니다~
그럼 이제 thr변수에는 다음과 같은 사진이 저장되겠습니다

네! 확실히 필터링이 잘 된것 같습니다!
d) 경계부분을 옆으로 번지게 한다
이제 이 뭉치를 바로 추출하기 전에 글자라는 것을 확실하게 하기위해 일부로 선을 번지게 만들겠습니다.
이번에도 아까와 마찬가지로 모폴로지연산을 할 것입니다. 근데 이번엔 gradient가 아닌 close연산을 해보도록 하겠습니다.

이렇게 opening은 잡음을 제거하는 용도로 약간 이미지들을 축소(?)시키는 반면 closing은 이미지를 부풀립니다.
쉽게 말하면 저희는 이 closing 연산을 통해 옆으로 이 글자를 옆으로 번지게 만듭니다.
kernel2 = np.ones((6, 15), np.uint8)
morph2 = cv2.morphologyEx(thr, cv2.MORPH_CLOSE, kernel2) # 4 ================ 뭉게기아까와 동일하지만 2번째 인자가 CLOSE로 바뀌고 커널도 kernel2를 사용했습니다. 저는 옆으로 번지게 하기 위해서
nxm커널의 m을 늘려 6x15커널을 사용했습니다. (자세한 설명은 위 b단계를 참고해주세요)
결과값은

이렇게 만족스럽게 나온 것 같습니다. 모폴로지 close연산덕분에 옆으로 번져서 단어 덩어리처럼 만든 겁니다!
위의 결과는 이제 morph2 변수에 저장됩니다~
e) 그 중 뭉텅이로 있는 부분을 추출한다
이제는 이 뭉텅이를 추출하기만 하면 끝납니다!
roi_list = []
contours, _ = cv2.findContours(morph2, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 5 ================ 특징점 찾기
org2 = cv2.copyMakeBorder(org, 0, 0, 0, 0, cv2.BORDER_REPLICATE)
for cnt in contours:
try:
x, y, w, h = cv2.boundingRect(cnt)
if w > 5 and 30 < h < 100:
roi = org2[y:y + h, x:x + w]
# cv2.imshow('roi', roi)
roi_list.append(roi)
cv2.rectangle(org, (x, y), (x+w, y+h), (255, 0, 0), 2)
except Exception as e:
pass여기서 가장 중요한 코드는 이 findContours라는 함수입니다
contours, _ = cv2.findContours(morph2, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 5 ================ 특징점 찾기이 findContours는 첫번째 인자로 grayscale이미지를, 뒤에 2개의 인자값들은 연산처리 알고리즘인데 이는 아래를 참고해주세요~


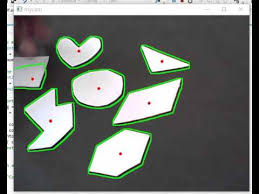
findContours는 위의 그림처럼 threshold한 결과의 윤곽선을 그리는 용도로 많이 사용됩니다.
이 함수는 특징점들을 리스트형태로 리턴합니다.
for cnt in contours:
try:
x, y, w, h = cv2.boundingRect(cnt)
if w > 5 and 30 < h < 100:
# print(w, h)
roi = org2[y:y + h, x:x + w]
# cv2.imshow('roi', roi)
roi_list.append(roi)
cv2.rectangle(org, (x, y), (x+w, y+h), (255, 0, 0), 2)
except Exception as e:
passcontours변수에는 이 특징점들이 리스트로 저장되어있고 cnt로 하나씩 받습니다.
그리고 이 boundingRect( ) 라는 함수에 이 특징점을 넣으면 이 특징점의 좌표와 길이 높이를 반환합니다
그 다음 if 조건문으로 길이가 5 이상이면서 높이가 30, 100사이인 특징점만 뽑아냅니다. 이 전처리가 없으면

이렇게 작은 것들까지 인식이 되서 신경망 학습할 데이터의 크기가 기하학적으로 늘어납니다. 그래서 저는
너비는 적당한 길이를 가지고(한 글자만 있는 경우도 있기 때문) 높이는 너무 크지않는 정도 (안그러면 기둥같이 좁고 길
쭉길쭉한 것들도 같이 인식이 됩니다....ㄷㄷㄷ)의 덩어리를 추출하게끔 설계했습니다~

대충 크기짐작은 이런식으로 했습니다ㅋㅋㅋㅋ
roi = org2[y:y + h, x:x + w]
# cv2.imshow('roi', roi)
roi_list.append(roi)
cv2.rectangle(org, (x, y), (x+w, y+h), (255, 0, 0), 2)여기서 org2를 만든 이유는 org가 슬라이싱이 안되서입니다...ㅠ
org2 = cv2.copyMakeBorder(org, 0, 0, 0, 0, cv2.BORDER_REPLICATE)요렇게 org(오리지널 사진)을 org2에 복사하였습니다~
따라서 org2는 org와 마찬가지로 numpy배열이겠죠. 마지막으로 우리가 찾은 이 덩어리를 잘라내야겠죠
ROI는 Region of Interest 의 약자로 관심역역만을 본다는의미죠
numpy배열은 일반배열처럼 슬라이싱을 지원하기때문에 슬라이싱으로 이미지를 잘라냅니다.


이렇게 잘린 사진들을 roi_list에 append합니다. 마지막으로 org에 cv2.rectangle로 사각형을 그립니다.
첫번재 인자는 사각형을 그릴 이미지, 두번째 , 세번째인자는 왼쪽위좌표와 오른쪽위좌표, 네번째 인자는 선의 색,
( ※ Opencv는 BGR로 읽기때문에 (255,0,0) 는 파랑색입니다 ) 다섯번째 인자는 두께입니다.
자 그럼 rectangle() 함수가 끝나고 최종적으로 반복문이 끝나면 처음의 org이미지는

이렇게 성공적으로 추출했네요!
다음포스터는 이를통해 동영상안의 텍스트까지 추출해보겠습니다
'Projects' 카테고리의 다른 글
| 빅데이터 분석으로 알아보는 코로나19 이후 문화산업 -2 (0) | 2020.08.12 |
|---|---|
| 빅데이터 분석으로 알아보는 코로나19 이후 문화산업 (0) | 2020.08.11 |
| 웹 컴파일러 만들기 프로젝트 - 1.웹 컴파일러 제작 (4) | 2020.06.11 |
| 웹 컴파일러 만들기 프로젝트 - 개요 (2) | 2020.03.04 |
| 물건 가져와주는 드론 제작과정 (2019.12.23 ~ 2020.1.20) (0) | 2020.01.20 |
Contents
소중한 공감 감사합니다