빅데이터 분석으로 알아보는 코로나19 이후 문화산업 -2
코로나 이후로 많은 산업들의 매출이 빠르게 감소하였습니다. 특히 영화나 관광산업은 코로나의 영향을 직격탄으로 맞았습니다.

2020년1월 이후로 매출이 큰 폭으로 감소한 것을 볼 수 있습니다. 하지만 분명 코로나임에도 불구하고 꾸준히 사람들이 찾거나, 코로나로 인해 매출이 더 오른 산업이 있을 것입니다. 이제부터 그런 문화,관광산업을 찾아보고 특징을 분석하여 다른 산업에도 적용을 해보겠습니다.

우선 사람들에게 각광받는 문화산업을 선정 -> 특징을 분석 -> 특징을 적용 순으로 진행하겠습니다.

사람들에게 각광받는 문화산업을 선정하기 위해 신한카드 사용내역 데이터를 사용하였습니다. 신한카드 데이터는 2017년부터 2020년까지의 데이터를 사용하였고 메모장파일로 저장이 되어있었습니다.

이런식으로 텍스트파일로 되어있는 데이터를 빠르게 처리하기 위해서 Mysql로 넣어서 관리할 예정입니다.
def insert(self, year, limit):
data_list = read_file(year, limit)
if data_list == None:
return
try:
with self.conn.cursor() as curs: # connect DB
# 거주지,카드이용주소(시도),(시군구), 업종 대분류, 업종소분류, 성별, 연령대, 이용년월, 요일, 이용시간대, 취급액, 이용건수
sql = 'INSERT INTO CardInfo VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);'
curs.executemany(sql, data_list)
self.conn.commit()
print("commit ok!")
except Exception as e:
self.e_querry.append(sql)
print(e)
finally: self.conn.close()
그냥 텍스트파일 한줄씩 읽고 하나씩 넣었습니다. 여기서 단순 반복문으로 insert를 하면 시간이 엄청 오래 걸리기 때문에 executemany로 한번이 insert작업을 하였습니다.
데이터베이스에 들어간 카드사용내역은 위와 같습니다. 옆에서부터 차례로
거주지, 카드이용주소(시도),(시군구), 업종 대분류, 업종소분류, 성별, 연령대, 이용년월, 요일, 이용시간대, 취급액, 이용건수 입니다. 이제 이 데이터를 업종소분류대로 분리를 하고 각 분류(이제부터 카테고리라 하겠습니다)마다 시간에 따라 변화한 카드사용횟수, 총 카드사용액, 카드이용자수를 추출해보겠습니다.
def save_dataset(self):
dic = {"cnt":{}, "c_sum":{}, "vlm_sum":{}, "dist":{}} # 이용자수, 카드 이용수, 지출액, 거리,
try:
with self.conn.cursor() as curs: # connect DB
curs.execute("SELECT DISTINCT gb2 FROM CardInfo")
category_list = curs.fetchall()
curs.execute("SELECT DISTINCT ta_ym FROM CardInfo ORDER BY ta_ym ASC")
year_list = curs.fetchall()
# curs.execute("SELECT * from (SELECT DISTINCT gb2 FROM Cardinfo) x CROSS JOIN (SELECT DISTINCT ta_ym FROM Cardinfo) TMP;")
# SELECT COUNT(*) as cnt, SUM(userc) as c_sum, SUM(vlm) as vlm_sum FROM CardInfo WHERE (ta_ym, gb2) IN (SELECT * from (SELECT DISTINCT gb2 FROM Cardinfo) x CROSS JOIN (SELECT DISTINCT ta_ym FROM Cardinfo) TMP;)
for category in category_list:
category = category[0]
dic["cnt"][category] = { }
dic["c_sum"][category] = { }
dic["vlm_sum"][category] = { }
dic["dist"][category] = { }
for year in year_list:
year = year[0]
# print(category, year)
curs.execute("SELECT COUNT(*) as cnt, SUM(userc) as c_sum, SUM(vlm) as vlm_sum, COUNT(CASE WHEN v1=v2 THEN 1 END) as dist FROM CardInfo where ta_ym = %s AND gb2 = %s", (year, category)) # cnt, c_sum, vlm_sum
cnt, c_sum, vlm_sum, dist = curs.fetchall()[0]
dic["cnt"][category][year] = cnt
dic["c_sum"][category][year] = int(c_sum)
dic["vlm_sum"][category][year] = int(vlm_sum)
dic["dist"][category][year] = int(dist) / int(cnt) * 100
savejson(dic, 'data/data4_sorted.json')
json.dumps(dic)
finally:
self.conn.close()
여기서 핵심은 SQL문입니다.
SELECT COUNT(*) as cnt, SUM(userc) as c_sum, SUM(vlm) as vlm_sum, COUNT(CASE WHEN v1=v2 THEN 1 END) as dist FROM CardInfo where ta_ym = %s AND gb2 = %s", (year, category)
이 SQL은 해당 year(년&월)과 category(업종소분류 -유흥,스키 등등)마다의 사용자수, 카드 총 이용수, 총 지출액, 단거리 이동(거주지와 카드 사용지가 같으면 단거리이동)횟수를 불러옵니다. 이런 데이터들을 json에 최종적으로 저장시킵니다.

json데이터는 이렇게 생겼습니다. dist속에 유흥 속에있는 2017~2020까지 데이터는 유흥카테고리에 해당하는 가게에 방문한 사람들의 수 데이터를 담고있습니다.
카테고리에는 골프, 공연관람, 관광쇼핑, 교육훈련, 교통, 독서, 레저스포츠, 목욕, 미술공예참여, 미용, 사진촬영, 숙박, 스키, 스포츠용품구매, 악기연주, 애완동물돌보기, 여행사, 외식, 운동경기관람, 유흥, 음악감상, 인터넷게임, 자전거, 종교활동, 종합쇼핑, 체험, 패션쇼핑, 헬스 이 28가지가 있는데, 이 28가지 중, 카드 사용횟수가 코로나시기 (2019-12월 ~ )에 상승하거나 유지하는 카테고리를 선택하려한다.

하지만 일반 json으로 텍스트데이터로 분석하려니 눈이 아프다.... 그래서 이 json데이터를 그래프로 표현하려한다.
def save_dataset2graph(self):
graph_data = []
data = openjson("data/data4_sorted.json")
# plt.style.use('dark_background')
# print(len(data.items()))
x = [0,1,2,3,4,5,6,7,8,9,10,11]
for d in ["cnt", "c_sum", "vlm_sum", "dist"]:
for category,year_dic in data[d].items():
# print(category, " & ", year_dic)
y1 = []
y2 = []
cnt = 0
for year, value in year_dic.items():
if 201807 <= int(year) <= 202006:
if cnt <= 11:
y1.append(value)
else:
y2.append(value)
cnt+=1
plt.cla();
plt.figure(figsize=[9,8])
plt.title(category, fontproperties=fontprop)
plt.xlabel("날짜", fontproperties=fontprop)
t = ''
if d=='cnt':
t = '이용자 수'
elif d=='c_sum':
t = '이용건수'
elif d=='vlm_sum':
t = '총 사용액수'
elif d=='dist':
t = '단거리 비율'
plt.ylabel(t, fontproperties=fontprop)
plt.xticks(x, ["07","08","09","10","11","12","01","02","03","04","05","06"])
plt.plot(x,y1 ,x,y2)
plt.savefig("./img/"+ d + "/" + category + '.png')
위의 코드는 방금 있는 json파일을 읽어서 그래프로 표현하는 함수입니다.
cnt = 0
for year, value in year_dic.items():
if 201807 <= int(year) <= 202006:
if cnt <= 11:
y1.append(value)
else:
y2.append(value)
cnt+=1
이 부분은 2018년 7월 부터 2020년 6월까지의 데이터를 그래프에 표시하기 위해 추가한 부분입니다.
y1과 y2는 각각의 그래프인데, 그래프를 2개만드는 이유는 작년대비 현재 동향이 어떻게 되는지를 살피기 위함입니다.
마지막 부분에 plt.savefig를 통해 이미지가 저장됩니다.

옆에서부터 차례대로 이용건수, 이용사주, 단거리비율, 총사용액수 입니다.

각각의 파일에는 각 카테고리마다의 동향을 나타낸 그래프가 있습니다.
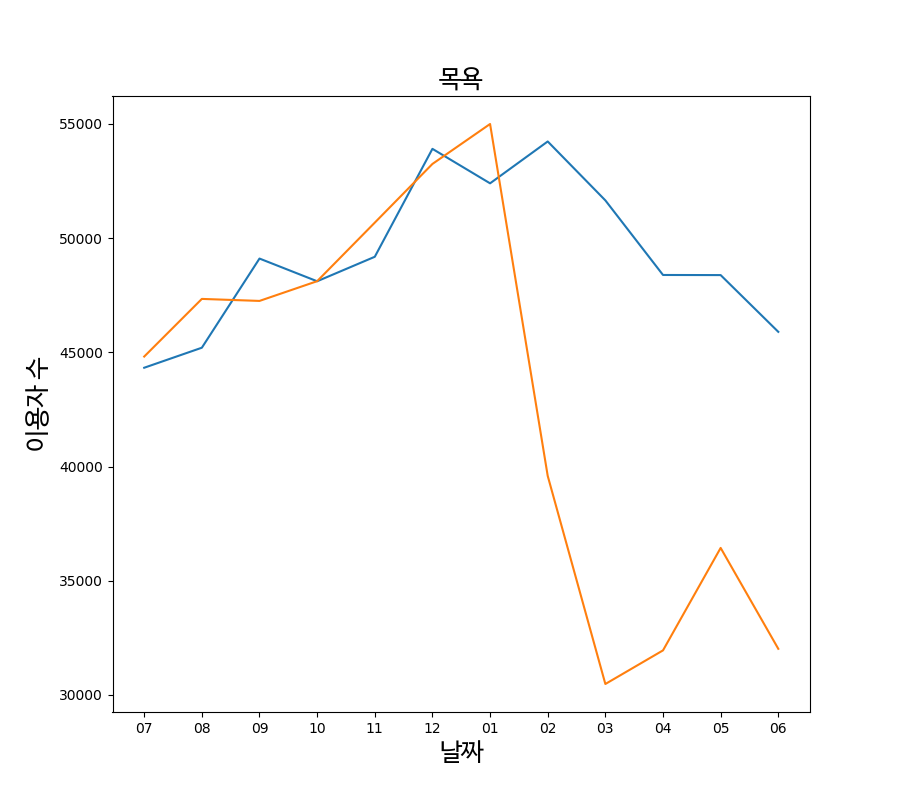
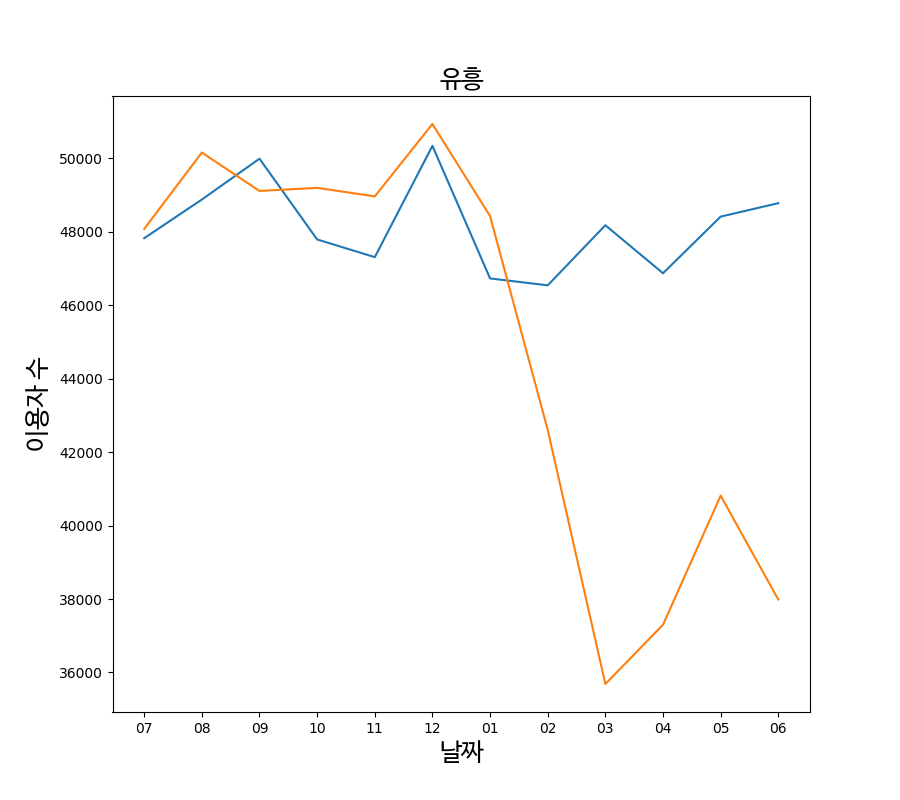
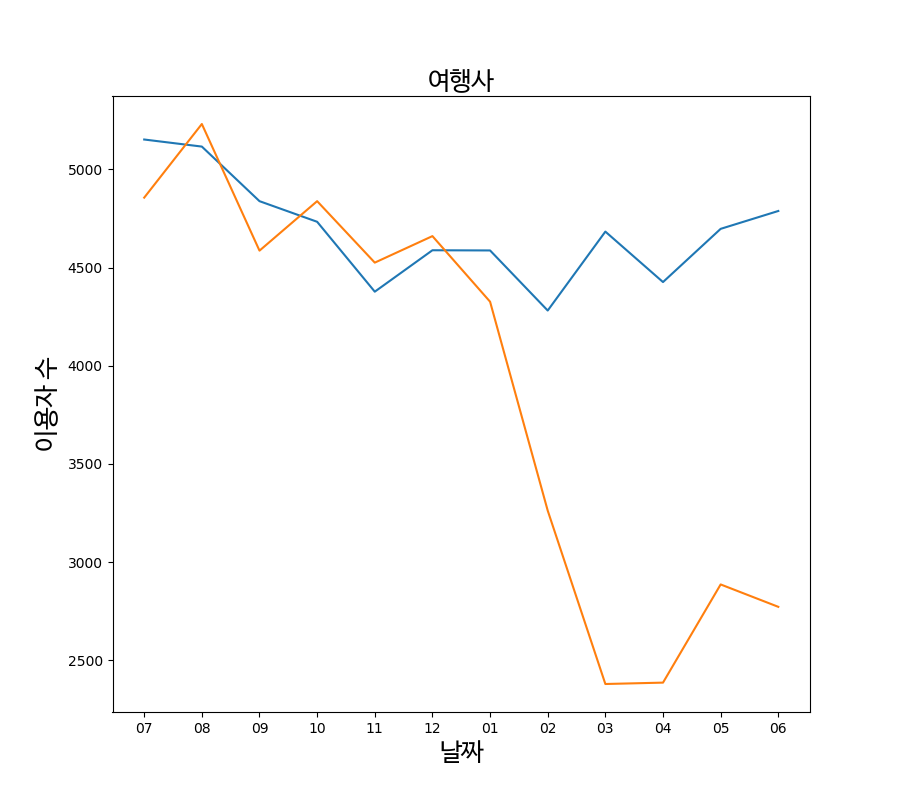
파란색 그래프는 2018년~2019년 데이터(작년동향) 그리고 주황색은 2019년~2020년 데이터입니다. 이 그래프를 보면 코로나시기 (12월 ~ 3월)때 작년에 비해 이용하는 사람들의 수가 대폭 감소하는 것을 볼 수 있습니다. 즉 코로나로 인해 피해를 많이 본 것을 알 수 있습니다.
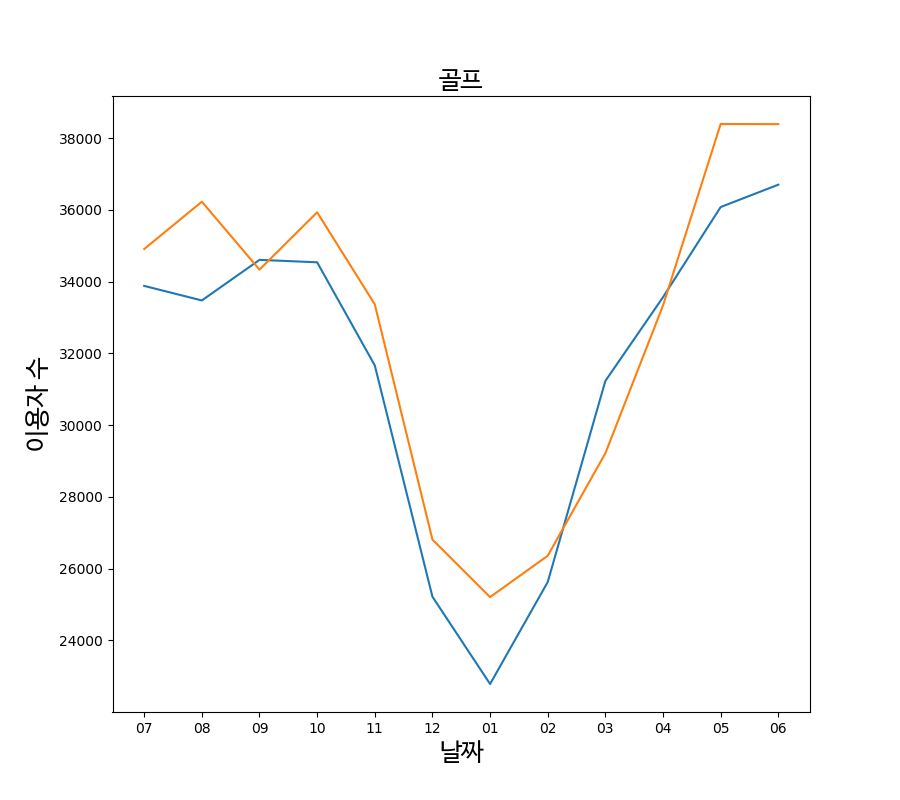
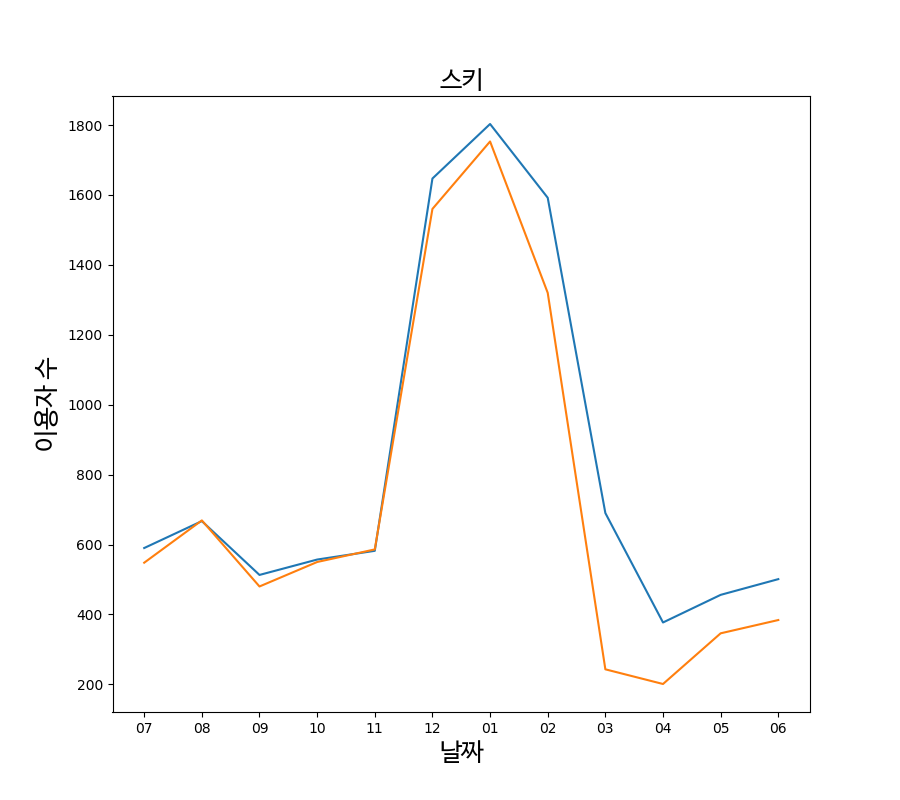
추가로 작년동향과 같이 따져봐야하는 이유는 골프나 스키처럼 계절성 문화산업일 경우를 생각해봐야하기 때문입니다. 스키가 코로나시기에 이용자가 많이 줄어든 것은 사실이지만, 스키는 겨울에 하는 스포츠이기 때문에 12월, 1월, 2월일때 이용자가 많고 나머지는 줄어들 수 밖에 없습니다. 단순히 코로나의 영향으로만 감소했다고 보기 힘들다는 것입니다. 실제로 작년과 비교해서 비슷하게 떨어졌습니다.
이렇게 28개를 일일히 주관적인 판단으로 사람들에게 각광받는 산업이라 단정지을 수 없으니 일정한 기준을 정하고
더 보기 좋게 정리하는게 좋겠습니다.
분류는 다음 포스팅 때 진행해보겠습니다